工业大模型为何难以应用
发布时间:2025-08-20
浏览次数:43
来源:独数易智
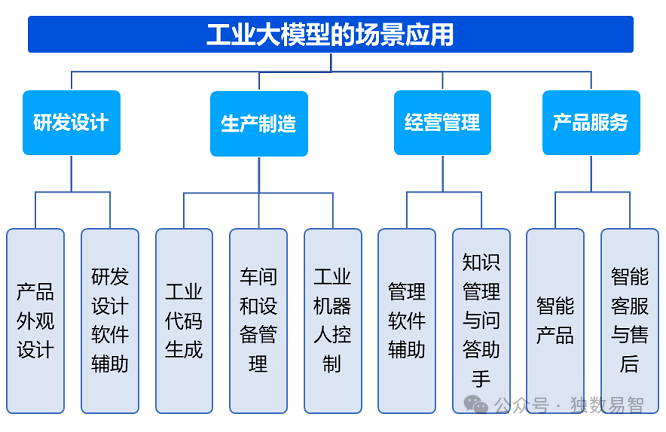
1. 数据质量和可靠性的挑战
2. 模型的复杂性和解释性问题
3. 高昂的算力成本
4. 行业知识的缺乏
5. 应用场景的限制


工业大模型(Industrial Large Models, ILMs)是工业4.0和智能制造背景下应运而生的前沿技术,利用大语言模型(LLMs)、大数据分析和深度学习模型来解决工业中的复杂应用和需求。核心优势在于能够结合通用知识或特定领域的知识来指导机器完成数据分析、预测和决策支持等任务。然而,尽管工业大模型拥有巨大的潜力,在实际落地和提升工业生产效率方面仍面临着一系列挑战。
模型的崛起有望在工业领域带来“基础模型+各类应用”的新范式。大模型凭借其卓越的理解能力、生成能力和泛化能力,能够深度洞察工业领域的复杂问题,不仅可以理解并处理海量的数据,还能从中挖掘出隐藏在数据背后的规律和趋势。
大模型应用落地需要深度适配工业场景。大模型的优势在于其强大的泛化能力,可以在不同的领域和任务上进行迁移学习,而无需重新训练。但无法充分捕捉到某个行业或领域的特征和规律,也无法满足某些特定的应用场景和需求,在真正融入行业的过程中,需要适配不同的工业场景,其核心就是要解决不懂行业、不熟企业、存在幻觉这三大问题。
数据是工业大模型的基石,但高质量数据的供给不足是一个主要问题。工业数据的收集、清洗以及治理工作本身充满挑战,数据安全和隐私保护的要求更是加剧了这一难题。此外,数据的非竞争性和非排他性特征在实际应用中也带来了管理和利用上的困难。
工业大模型的复杂性不仅体现在技术层面,还涉及到模型的透明度和可解释性。随着应用的复杂性增加,单一模型已无法满足所有需求,集成学习和多模型协同成为发展趋势。同时,模型的参数众多,这不仅带来了解释速度的挑战,也增加了模型的解释难度。
训练大型模型需要巨大的算力支持,这导致初期的算力成本非常高。例如,微软与英伟达合作推出的Megatron Turing-NLG模型训练成本可达数百万美元。此外,算力资源的分散和调度管理能力的不足也增加了成本。
通用大模型在特定行业应用时,往往缺乏深入的行业知识,这限制了它们解决行业复杂任务的能力。此外,高质量语料的短缺限制了大模型的发展,特别是在中文语料方面。
5. 应用场景的限制
尽管工业大模型在多个场景中有应用潜力,但在具体应用层面,如工艺设计等,仍存在适应性问题。数据和模型质量问题、应用成本挑战、模型应用的可靠性以及自动化和自适应性的不足都是需要解决的问题。
训练大模型的成本和技术壁垒较高,这对于中小企业来说可能是难以逾越的障碍。工业大模型的应用不仅需要大量的资金投入,还需要专业的人才支持,这进一步增加了企业的负担。
尽管存在诸多挑战,工业大模型的应用被视为推动制造业高质量发展的重要手段。未来,工业大模型产业将朝着定制化、边缘计算、产业协作等方向发展,更加注重满足特定行业或应用场景的需求,以及与产业的深度融合和协作。
工业大模型的发展和应用是一个复杂而多维的过程,它不仅需要技术上的突破,还需要行业知识、数据治理、算力资源和成本控制等多方面的协同发展。随着技术的不断进步和产业的深入合作,工业大模型有望在未来的工业生产中发挥更加重要的作用,推动制造业向更高效率、更低成本和更智能化的方向发展。